注:本文描述了https://github.com/versatica/mediasoup/issues/769的排查过程
问题描述
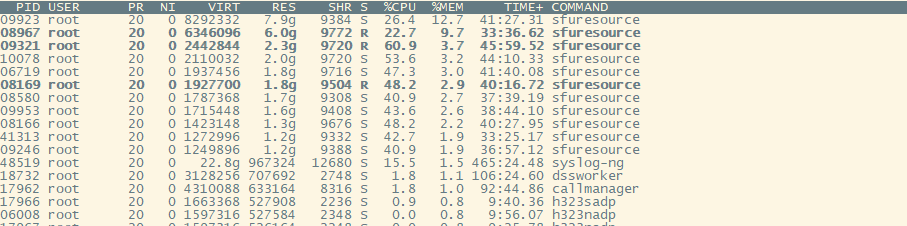
Mediasoup主要负责 RTC会议中的音视频码流转发,单线程多进程模型。一个进程一般接入40~50个终端,占用900MB左右内存。
一日,测试反馈,其环境中多个Mediasoup进程,内存占用超过了2G,并且在结会后,内存也不会释放。
Mediasoup在公司实验局上已经运行了半年之久, 并没有发现存在内存泄漏的问题,其他测试也没有反馈过类似的问题,说明这不是一个常见的问题,而是在满足特定条件下才能复现的问题,因此我们需要进一步找出这个问题的复现条件。
与测试沟通后,得知这个问题是在每晚的拷机后出现的,拷机的步骤是呼叫500~600个带码流的模拟终端,反复进会退会。
可以判定,这个问题可能和大容量有关,只有在大容量的环境下才会复现,而实验局和一般的日常测试,并不会有这么大的容量。
进一步沟通后,又得到了一个重要的信息:只有在单电口的时候才能复现,网口聚合或者使用光口的时候,无法复现。
根据上述信息,我尝试复现了几次,发现单网口下,的确会出现内存不断上涨的问题,同时我还延长了测试时间,想看看内存最高会涨到多少,结果内存一直涨到了12G。
一个问题,如果找到了复现的步骤,那就已经解决了一半。问题可复现,我们就可以对各种假设进行尝试和验证,甚至增加更多的打印和调试信息。
根据上述信息,结合复现的场景,推测问题可能和大容量下,丢包重传有关,但检查了相关代码后,没有发现明显的指针释放问题。
内存泄露的类型
内存泄露是软件开发中一种比较常见的问题,一般来说,典型内存泄露就是在使用new或者malloc申请内存后,没有调用delete或free进行释放。当然,我们有时可能会申请一段固定大小的全局buffer,并且在程序的生命周期内都不会主动释放,这种可控的行为,一般不认为是内存泄露。
还有一种隐性的内存泄露,比如我们在程序中使用了一些容器对象,如vector或map,运行过程中不断地往里面增加成员,但却没有在正确的时机进行删除。虽然最终在容器对象销毁时会自动释放相关内存,但可能在容器生命周期内,被塞入了过多的对象,而导致OOM。
内存泄露检测工具
有很多内存泄露检测工具,Linux常用的有Valgrind,AddressSanitizer,TCMalloc,Windows下有Visual Leak Detect、以及Visual Studio自带的内存分析器。
Valgrind
Valgrind是一套内存检测、性能监控的工具集,可以用来分析各类内存越界及泄露问题,也可以用来分析程序性能。
可以把Valgrind视为一个虚拟机,我们的程序会在Valgrind虚拟出来的环境里运行,因此Valgrind可以记录程序每一次的内存申请和函数调用,并生成报告以供分析。
我们需要通过Valgrind来运行我们的程序,如:
valgrind --leak-check=yes ./test
程序退出后,valgrind会输出一份报告,告诉我们哪些内存未被主动释放。
Valgrind的优点是,它对程序是无侵入式的检测,我们不需要重新编译程序即可进行检测。
但Valgrind的实现方式对程序的性能有较大的影响,一般会导致程序的运行速度降低10倍左右。
AddressSanitizer
AddressSanitizer是Google开发的一种内存检测工具,可以检测多种内存问题,如内存泄露、内存越界、重复释放等等。
AddressSanitizer已经被内置到了GCC和Clang编译器中,因此只要在编译的时候,加上相关编译选项,并链接AddressSanitizer依赖库就能启用。
AddressSanitizer与Valgrind的原理不太相同,他是通过在编译期的插桩及运行期的函数劫持,来实现对内存相关操作的监控和分析。
我们可以通过在编译时加上-fsanitize=address编译选项,来开启内存检测功能。
程序在正常退出后,AddressSanitizer会输出一份报告,告诉我们哪些内存未被主动释放。
AddressSanitizer的优点是对程序性能的影响较小,一般运行速度降低2倍左右。
但缺点是程序需要重新编译才能启用AddressSanitizer。
GooglePrefTools
GooglePrefTools是Google提供的一套基于TCMalloc实现的内存检测及性能分析工具,可以用于检测多种内存问题,如内存泄露、内存越界等,以及对程序的性能进行分析。
TCMalloc,全名Thread-Caching Malloc是一个Google内部开发的一个内存分配库,用于替代glibc里的默认内存分配库ptmalloc。其主要特点在于,为每个线程开辟了独立的内存缓存空间,以减少对全局内存锁的占用。
在GitHub上有两个TCMalloc的页面,一个是https://github.com/gperftools/gperftools,另一个是https://github.com/google/tcmalloc。两者的均源自google内部开发的内存分配库,前者提供了众多程序分析及调优工具,而后者主要专注于内存分配库本身,因此这里我们主要使用的是前者。
TCMalloc的原理是重载了C++中的new、delete及C中的malloc、realloc、calloc、free等函数,因此TCMalloc就可以感知我们每次对内存的申请释放操作,并进行分析。
TCMalloc提供了HeapChecker(内存泄露检测)、HeapProfiling(内存快照及分析)、CPUProfiler(CPU性能检测)等工具。
我们可以通过不同的方式使用TCMalloc:
- 主动包含TCMalloc的头文件,并使用TCMalloc提供的相关工具类,来进行内存泄露的检测。
- 使用
LD_PRELOAD方式预加载TCMalloc库,并通过一系列环境变量控制各项功能的开关,而无需重新编译程序。
TCMalloc的优点在于,它支持无侵入式的检测,无需重新编译程序。
同时TCMalloc支持截取堆快照,并提供了工具,对不同的堆快照进行比较,这样我们可以直观地分析出当前程序的内存分配情况,以及不同时间点,内存的增减情况。
TCMalloc可以很好地解决一些程序无法正常退出的场景,以及前面所说的隐形的内存泄露。
问题分析
回到这次的问题,问题主要有两个现象:
- 内存特性场景下在不断增长
- 内存在资源释放后没有减少
从现象上来看,可能是申请的内存自始至终就没有释放,因此我先尝试运行一遍程序,复现一下问题,再让程序正常退出,看看有没有内存在程序退出时没有被正常释放。
由于这个问题只有在大容量下才能复现,而Valgrind对性能的影响又比较大,因此我们使用AddressSanitizer来进行分析。
使用AddressSanitizer
通过在程序的编译脚本中增加-fsanitize=address参数,重新编译了Mediasoup,然后开会、呼叫500个终端、等待内存增长、结会、通知程序退出。
AddressSanitizer输出的报告里,并没有提示存在内存泄露,但我们的的确确在top和ps命令里看到,程序占用了很大的内存,且在我们将所有码流传输资源都销毁的情况下,内存占用没有明显的减少。
为了避免是工具的问题,我又反复运行了多次,依然没有报告存在内存泄露的问题,这就说明,程序在退出的时候,内存的确已经被释放了。
为了找出到底是哪个依赖库或者对象占用了大量的内存,我在程序退出的地方加了多个sleep,以观察是释放哪个库的时候,内存有明显的减少。
但测试下来发现,并没有观察到哪个库释放的时候,内存占用有明显下降,且所有库都释放完后,内存占用依然高达700MB+。
这条路看来暂时是走不通了,因此我们需要转变思路,看看到底这些内存是由谁申请的,如果知道这些内存都是谁申请的,就可以进一步分析代码,看看这些申请的内存,有没有被正确的被释放。
使用TCMalloc
这时就需要TCMalloc出场了,可以用它为程序生成堆快照,记录某一时刻有哪些代码申请了多少内存。通过比较不同时刻的堆内存快照,我们就可以知道,这些多出来的内存,到底是被谁占用的了。
我们可以通过设置HEAPPROFILE环境变量,来指定快照生成的路径:
export HEAPPROFILE=/tmp/test.hprof
TCMalloc支持多种方式抓取快照:
| 环境变量 | 默认值 | 说明 |
|---|---|---|
HEAP_PROFILE_ALLOCATION_INTERVAL |
1073741824 (1 Gb) | 每当程序内存申请达到了指定字节数时转储堆分析信息 |
HEAP_PROFILE_INUSE_INTERVAL |
104857600 (100 Mb) | 每当高水位内存增涨指定的字节数时转储堆分析信息 |
HEAP_PROFILE_TIME_INTERVAL |
0 | 每经过指定的秒数时转储堆分析信息 |
HEAPPROFILESIGNAL |
disabled | 每当收到指定信号时转储对分析信息 |
为了更好地控制堆快照的抓取时机,我们使用信号量来通知TCMalloc抓取快照:
export HEAPPROFILESIGNAL=12
同时我们可以使用预加载库的方式,用TCMalloc替换掉默认的内存分配库:
export LD_PRELOAD="/usr/lib/libtcmalloc.so"
程序运行起来后,我们在内存增长前和增长后,分别调用kill -12 pid命令给程序发送信号量,让TCMalloc生成堆快照。
我们得到了两个快照文件,/tmp/profile.0001.heap和/tmp/profile.0002.heap,并使用以下命令比较两次的快照:
pprof --base=/tmp/profile.0001.heap /opt/mediasoup /tmp/profile.0002.heap
通过输出的结果,可以看到,有将近1G的内存都是在UdpSocketHandler::Send这个函数申请且尚未释放的。

那这个函数里面做了些什么操作呢,我们来看看源码:
void UdpSocketHandler::Send(
const uint8_t* data, size_t len, const struct sockaddr* addr, UdpSocketHandler::onSendCallback* cb)
{
.....
// First try uv_udp_try_send(). In case it can not directly send the datagram
// then build a uv_req_t and use uv_udp_send().
uv_buf_t buffer = uv_buf_init(reinterpret_cast<char*>(const_cast<uint8_t*>(data)), len);
int sent = uv_udp_try_send(this->uvHandle, &buffer, 1, addr);
// Entire datagram was sent. Done.
if (sent == static_cast<int>(len))
{
// 回调发送成功
return;
}
else if (sent >= 0)
{
// 回调发送失败
return;
}
auto* sendData = new UvSendData(len);
sendData->req.data = static_cast<void*>(sendData);
std::memcpy(sendData->store, data, len);
sendData->cb = cb;
buffer = uv_buf_init(reinterpret_cast<char*>(sendData->store), len);
int err = uv_udp_send(
&sendData->req, this->uvHandle, &buffer, 1, addr, static_cast<uv_udp_send_cb>(onSend));
if (err != 0)
{
if (cb)
(*cb)(false);
// Delete the UvSendData struct (it will delete the store and cb too).
delete sendData;
}
else
{
// Update sent bytes.
this->sentBytes += len;
}
}
简单来说,就是先尝试用uv_udp_try_send以同步的方式发送一次数据,如果返回了EAGAIN,就new一个UvSendData对象,并将待发送的数据和回调函数复制进去,然后用uv_udp_send以异步的方式发送对象。
这段代码里,UvSendData的泄露嫌疑最大,那他是什么时候销毁的呢?可以看到,在发送完成的回调函数里,会删除UvSendData对象。乍一看,这段代码好像并没有明显的内存泄露问题。
如何证明UvSendData发生了内存泄露呢?于是我在UvSendData类中加了四个静态变量,记录创建的UvSendData对象的总数及大小,以及未释放的对象的总数及大小:
struct UvSendData
{
explicit UvSendData(size_t storeSize)
{
this->store = new uint8_t[storeSize];
this->storeSize = storeSize;
++totalNumber;
++leftNumber;
totalSize += storeSize;
leftSize += storeSize;
}
// Disable copy constructor because of the dynamically allocated data (store).
UvSendData(const UvSendData&) = delete;
~UvSendData()
{
delete[] this->store;
delete this->cb;
--leftNumber;
leftSize -= this->storeSize;
}
static uint64_t totalNumber;
static uint64_t leftNumber;
static uint64_t totalSize;
static uint64_t leftSize;
size_t storeSize{ 0 };
uv_udp_send_t req;
uint8_t* store{ nullptr };
UdpSocketHandler::onSendCallback* cb{ nullptr };
};
然后重新复现问题,分别在内存增长到比较大的时候,和资源全部销毁以后,输出了两次打印:
内存泄露时:
"uvDataLeftNum": 246449, "uvDataLeftSize": 83873064, "uvDataTotalNum": 7701001, "uvDataTotalSize": 2638616809
资源全部销毁后:
"uvDataLeftNum": 0, "uvDataLeftSize": 0, "uvDataTotalNum": 8230162, "uvDataTotalSize": 2818795277
通过上述数据,可以得出两个结论:
- 在内存泄露的时候,的确存在
UvDataSend对象没有释放 - 当资源全部释放后,
UvDataSend对象并没有泄露,而是全部释放了
这解释了为什么程序的内存会一直增高,但似乎还是无法解释为什么资源销毁后,内存不会及时释放。
先不管释放的问题,我们先看看为什么UvDataSend对象会不断增多,回顾问题复现的场景:在一个单电口的环境下,呼入500~600个2M终端,内存随着时间的推移不断增长。这里的问题关键在于,单电口、500~600个2M终端,也就是说,发送带宽超过了网口的实际速率。所以才有大量的数据包无法通过uv_udp_try_send接口同步发送,而是要使用uv_udp_send异步发送。随着排队的包数不断累积,内存不断增大。
这也解释了为何这个问题只有测试在单网口的环境里才能复现,光口、网口聚合的环境里都没有出现过,公司实验局也没有出现过,因为这些环境,发送带宽都没有超过网口速率。
再回到资源销毁不释放的问题,为何UvDataSend对象销毁后内存没有即时释放呢?
经过进一步的分析和思考,我怀疑可能是由于内存分配机制里的缓存导致的内存不释放问题。也就是实际上占用内存的对象已经销毁了,但内存分配器并没有把内存还给操作系统,而是缓存了下来,以便下次我们申请内存的时候可以复用。
内存分配机制
Linux中,提供了两组函数用来向操作系统申请内存,分别是brk()/sbrk()以及mmap()/munmap(),C++中的new、delete,C中的malloc、free等函数的底层实现就是用的上述两组函数,两组函数的差别在于:
brk()是通过推高进程的堆顶,来实现内存的分配,一般用于小块的内存分配,且释放时,不会直接还给操作系统,而是当堆顶的连续空闲内存到128K时,才会还给操作系统。
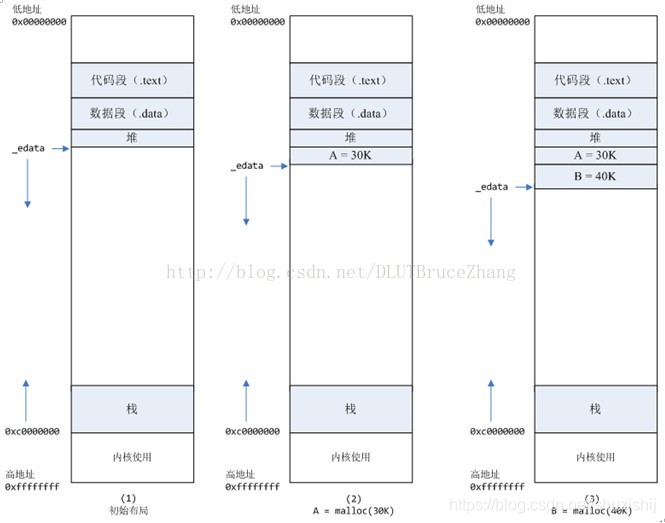
mmap()则是在进程的虚拟内存地址中,找一段空闲的地址,直接返回,一般用于大内存分配,释放后直接返还给操作系统。
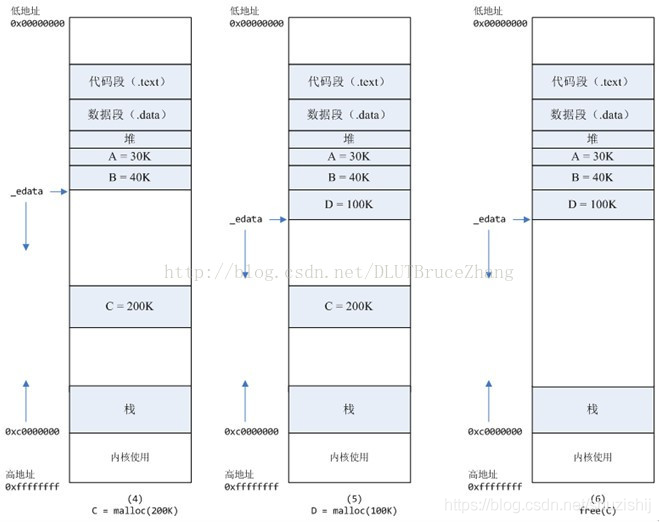
一般大、小内存以128K为界,所以当频繁分配小内存,且释放不连续时,通过brk()申请的内存就可能出现碎片或空洞,从而导致无法释放给操作系统。
回到问题本身,UvSendData的构造函数中恰好会分配一个用于存储待发送数据包的buffer,且这个buffer大小一般不会超过1500字节。所以可以判定,UvSendData构造函数里申请的内存是通过brk()方式申请的。因此怀疑资源释放后内存不释放的问题,是由于libc库未能将内存还给操作系统导致的,但还需要证据来进一步证明这一点。
通过各种搜索,找到了malloc_trim(0)这个函数,调用它可以主动触发进程将堆顶空闲的内存还给操作系统,我们可以尝试在资源释放完成后,手动调用这个函数看看是否能将进程的空闲内存还给操作系统。
调用前:
root 404394 34.9 4.0 2655284 2632912
调用后:
root 404394 34.5 0.0 2655156 23004
可以看到,调用了malloc_trim后,内存从2.6GB降到了23MB左右,效果显著。
通过上述的测试,基本证明了我们的猜想,内存并没有泄露,而是被ptmalloc缓存了。
但此处依然存在一个疑问,很多网上的文章在描述malloc_trim时,都说它只会释放堆顶的连续内存,既然堆顶有如此大的连续空闲内存,为何ptmalloc没有自动把内存还给操作系统呢?
在maclloc_trim的帮助文档里找到了答案:
Since glibc 2.8 this function frees memory in all arenas and in
all chunks with whole free pages.
Before glibc 2.8 this function only freed memory at the top of
the heap in the main arena.
解决方案
最终我们定位到了问题的原因:
- 由于特定的测试场景,导致码流发送速率高于网口传输速率,因而造成了发送数据积压,占用了大量的内存
- 由于使用了大量的小块内存来保存待发送的数据包,导致glibc未能将内存及时归还给操作系统
对于第一个问题,首先我们在用户的使用场景上就需要进行规避,避免用户在单台机器上接入超出网口速率的终端。其次,由于音视频码流本身就存在较强的实时性,排队过久的码流包本身也失去了意义,因此可以为排队的数据设置一个上限,队列满了以后就直接丢弃后续的数据。
对于第二个问题,可以通过使用内存池,一次性申请一块连续的大内存,这样可以通过mmap来分配内存。我们也可以使用第三方的内存分配器来替代glibc内置的ptmalloc库,常见的第三方库有Google的tcmalloc,facebook的jemalloc。
针对本案例中的问题,我也对tcmalloc和jemalloc进行了测试:
tcmalloc的表现与ptmalloc类似,在资源释放后,并没能将内存还给操作系统。
jemalloc的表现则非常亮眼,资源释放后,内存占用仅比刚启动时高了十几MB。
老哥牛B